


从 url 输入到返回请求的过程
一图胜千言
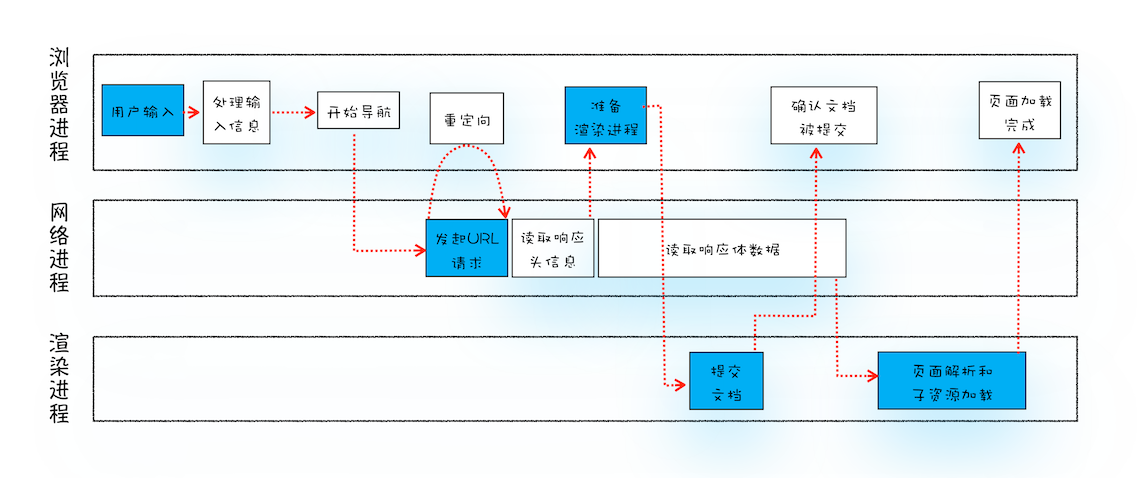
第一步:用户输入
当用户在地址栏中输入一个查询关键时,地址栏会判断输入的关键字是搜索内容,还是请求的 url
- 如果是搜索内容,地址栏会使用浏览器默认的搜索引擎,合成新的带搜索关键字的 url
- 如果判断输入内容符合 URL 规则,比如输入 www.baidu.com,那么地址栏会根据规则,把这段内容加上协议合成完成的 URL,如https://www.baidu.com
当用户输入关键字并键入回车之后,这意味着当前页面即将要被替换成新的页面,不过在这个流程继续之前,浏览器还给了当前页面一次执行 beforeunload 事件的机会,beforeunload 事件允许页面在退出之前执行一些数据清理操作,还可以询问用户是否要离开当前页面,比如当前页面可能有未提交完成的表单等情况,因此用户可以通过 beforeunload 事件来取消导航,让浏览器不再执行任何后续工作。
第二步:开始导航
是否有缓存,
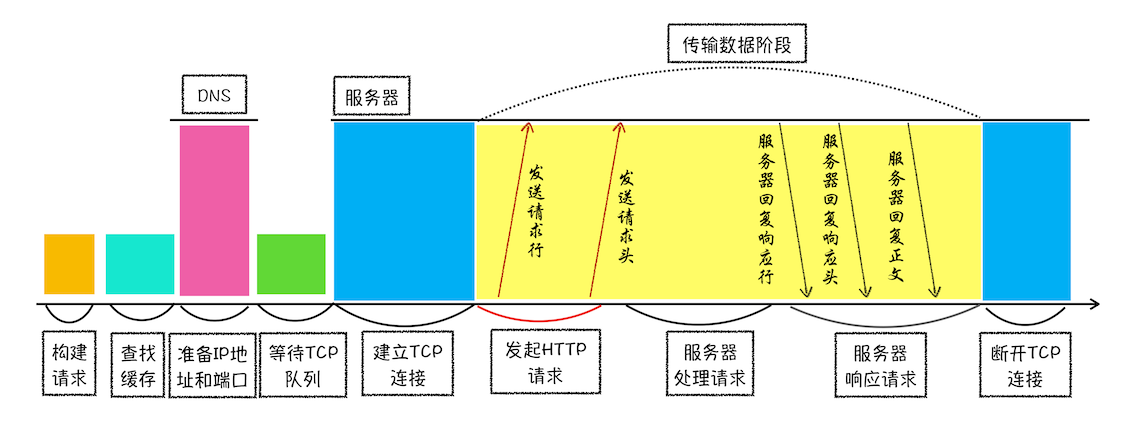
首先,网络进程会查找本地缓存是否缓存了该资源。如果有缓存资源,那么直接返回资源给浏览器进程;如果在缓存中没有查找到资源,那么直接进入网络请求流程。这请求前的第一步是要进行 DNS 解析,以获取请求域名的服务器 IP 地址。如果请求协议是 HTTPS,那么还需要建立 TLS 连接
接下来就是利用 IP 地址和服务器建立 TCP 连接。连接建立之后,浏览器端会构建请求行、请求头等信息,并把和该域名相关的 Cookie 等数据附加到请求头中,然后向服务器发送构建的请求信息
服务器接受到请求信息后,会根据请求信息生成响应数据(包括响应行、响应头和响应体等信息),并发给网络进程。等网络进程接受了响应行和响应头之后,就开始解析响应头的内容
第三步:读取响应
服务器返回的响应体到来之后,网路线程会检查接收到的前几个字节。如果是 HTML、CSS、JavaScript 文件,那下一步就是把数据交给渲染器进程,如果是一个 zip 文件或其他文件,那就意味着是一个下载请求,需要把数据传给下载管理器
第四步:联系渲染器进程
第五步:提交导航
第六步:初始化加载完成
这个过程可以大致描述为如下:
- 首先,用户从浏览器进程里输入请求信息
- 然后,网络进程发起 URL 请求
- DNS 查找
- 请求建立 TLS 连接
- 这里可能还会又 301 重定向
- 服务器响应 URL 请求之后,浏览器进程就又要开始准备渲染进程了
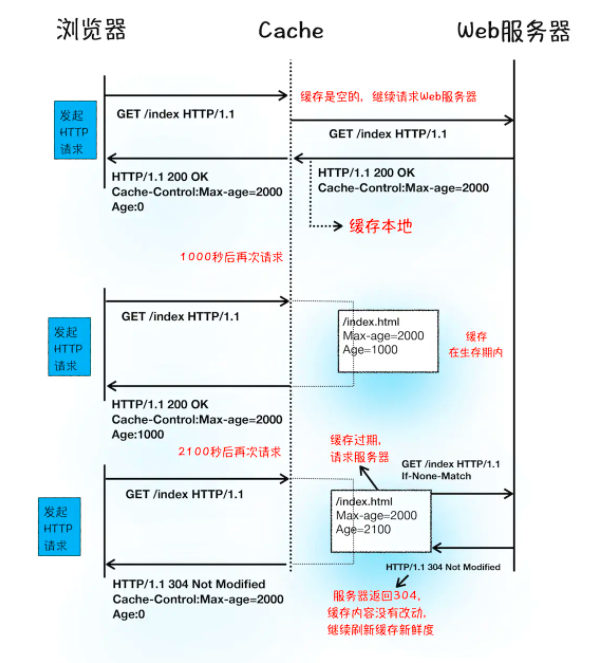
浏览器资源缓存
渲染进程内部包含主线程、工作线程、合成线程和光栅线程
Q&A
Q:老师,在做前端页面的时候,是否可以设置当前页面是否可以被缓存,以及哪些部分可以被缓存?还是说整个缓存机制都是由浏览器自己控制的?
A:作者回复: 是没有办法通过前端代码来控制缓存的,缓存是后端或者部署的同学来控制的,但是前端同学应该知道那些内容要被缓存,和后端或者部署的同学配合来打!
Q:请问:请求行和请求头是发送两次吗? 从文章的文字来看,是发送两次。 但我感觉是发送一次,即发送一次请求,该请求包含请求行和请求头。
A:作者回复: 对,只发送一次。
问下文章什么地方让你感觉是发送了两次啊?
我检查下。
Q:老师您好,我有 2 个问题:1,浏览器缓存 DNS 的解析结果,这个缓存是缓存到浏览器进程中吗?是不是浏览器关闭后浏览器的这个 DNS 的缓存也一起清除了?2,浏览器打开某个站点页面后,这个页面里面还有很多的域名需要解析例如一些图片的链接,这些解析结果都会缓存吗?
A:作者回复: 第一个问题:dns 缓存是保存浏览器本地的,下次启动依然有结果!
第二个问题:图片和其他域名都一样的,都会缓存的