


垃圾回收机制
灵魂三问:什么是垃圾回收,回收的是什么?为什么要有这东西?本文会介绍并尝试回答这三个问题
什么是垃圾回收?
在说这个东西之前,先要解释什么是内存泄漏,因为内存泄漏了,所以引擎才会去回收这些没有用的变量,这一过程就叫垃圾回收
什么是内存泄漏?
程序的运行需要占用内存,当这些程序没有用到时,还不释放内存,就会引起内存泄漏。举个通俗的例子,就好比占着茅坑不拉屎,坑位(内存量)就这么多,你还不出去(释放内存),就会引起想拉的人不能拉(系统变卡,严重点的会引起进程崩溃)
也就是说不再用到的内存,没有及时释放,就被称为内存泄漏。而内存泄漏,会让系统占用极高的内存,让系统变卡甚至奔溃。所以会有垃圾回收机制来帮助我们回收用不到的内存
当我们遇到遇到内存泄漏时,我们需要做什么呢?
不需要做任何事,因为 JavaScript 中的垃圾回收是自动的
如果你看过《JoJo的奇妙冒险:不灭钻石》,就知道替身中有自动型的替身
如吉良吉影的替身「杀手皇后」的第二形态:枯萎穿心攻击
在 JavaScript 的世界里,JavaScript 引擎会自动执行命令,帮我们清理用不到的变量(即减少内存开销)
当然,不同的语言采用不同的内存管理方式,大多数语言采用的是自动内存管理
自动内存管理(垃圾回收)阵营:
JavaScript、Java、Go、Python、PHP、Ruby、C#
手动内存管理阵营:
C、C++、Rust
回收的是什么
现在我们可以回答第二个问题:回收什么?
回收内存。清理变量,释放内存空间
为什么要有这东西
为什么要有垃圾回收呢?在前文的描述中,我们讲到过,如果任由内存泄漏,会让系统变卡甚至崩溃。导致这问题的原因是 JavaScript 的引擎 V8 只能使用一部分内存,具体来说,在 64 位系统下,V8 最多只能分配 1.4G;在 32 位系统中,最多只能分配 0.7G
因为使用内存大小上限,所以当有用不到的变量时,引擎会帮我们清理掉
这里我们不禁会想,这东西是怎么运行的?怎么知道我的变量哪些是用不到的?把正在用的变量清除掉会怎么样呢?
带着这个问题我们了解下垃圾回收的运行机制
垃圾回收运行机制
在说这个话题前,我们先回顾下,在 JavaScript 由什么组成 中曾经介绍过,JavaScript 的数据类型可分为基本类型和引用类型。基本类型存在栈内存,引用类型存在堆内存
但是我们那时没有解释为什么基本类型要存在栈中,引用类型要存在堆中。只是介绍,因为基本类型所花销的内存小,而引用类型所花销的内存大,而这恰恰是分两个空间存放不同数据的原因
在 JavaScript 中,引擎需要用栈来维护程序执行时的上下文状态(即执行上下文),如果栈空间大了的话,所有数据存放在栈空间中,会影响到上下文切换的效率,从而影响整个程序的执行效率,所以占内存大的数据会放在堆空间中,引用它的地址来表示这个变量
堆内存的分类
一个 V8 进程的内存通常由以下部分组成
- 新生代内存区(new space)
- 老生代内存区(old space)
- 大对象区(large object space)
- 代码区(code space)
- map 区(map space)
其他几个不重要,关键是新生代(内存)和老生代(内存)。针对新生代和老生代,引擎采用了两种不同的垃圾回收机制
新生代与老生代的垃圾回收
在介绍两种垃圾回收机制前,要先知道两个知识点:代际假说和分代收集
代际假说有以下两个特点:
- 大部分对象在内存中存活的时间很短,简单说,就是很多对象一经分配内存,很快就变得不可访问
- 不死的对象,会活得更久
因为有代际假说的认知,所以我们在垃圾回收时,会根据对象不同的生存周期采用不同的算法,其中 V8 把堆内存分为新生代和老生代两个区域(其他几个区域用处不大)
新生代中存放生存时间短的对象,老生代存放生存时间久的对象
为此,新生代区通常只支持1~8M 的容量,而老生代区会支持更大的容量,而针对这两块区域,V8 分别使用两个不同的垃圾回收器
- 主垃圾回收器,负责老生代的垃圾回收
- 副垃圾回收器,负责新生代的垃圾回收
我们先说说副垃圾回收器时如何处理垃圾回收的
新生代内存回收
新生代采用的是 Scavenge 算法,所谓 Scavenge 算法,是把新生代空间对半分为两个区域,一半是对象区域(from),一半是空闲区域(to)。如下图所示:
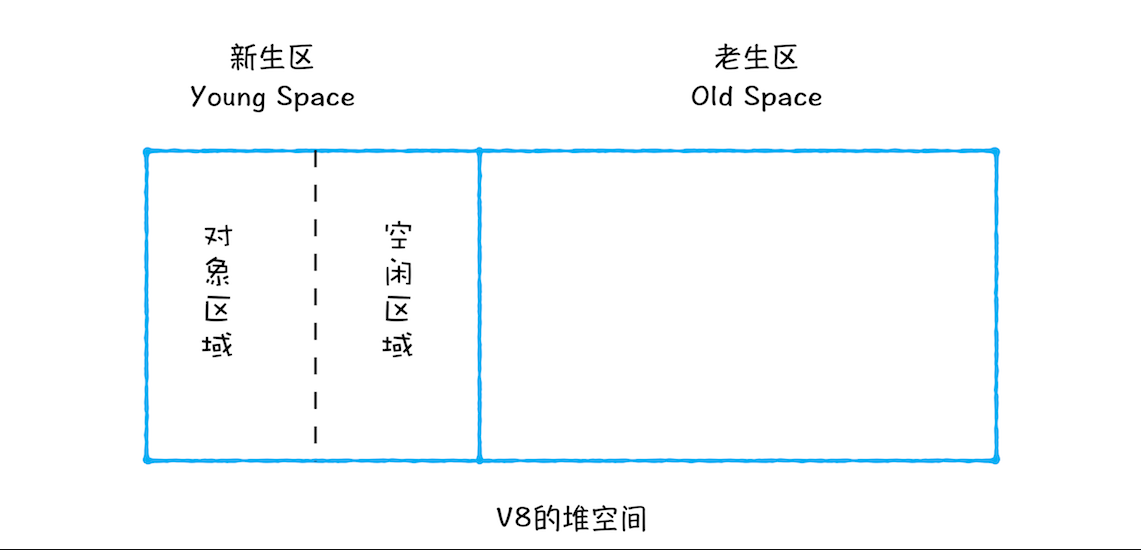
新的对象会首先被分配到对象(from)空间,当对象区域快写满时,就需要执行一次垃圾清理操作。当进行垃圾收回时,先将 from 空间中存活的对象复制到空闲(to)空间进行保存,对未存活的空间进行回收。复制完成后,对象空间和空闲空间进行角色调换,空闲空间变成新的对象空间,原来的对象空间则变成空闲空间。这样就完成了垃圾对象的回收操作,同时这种角色调换的操作能让新生代中的这两块区域无限重复使用下去
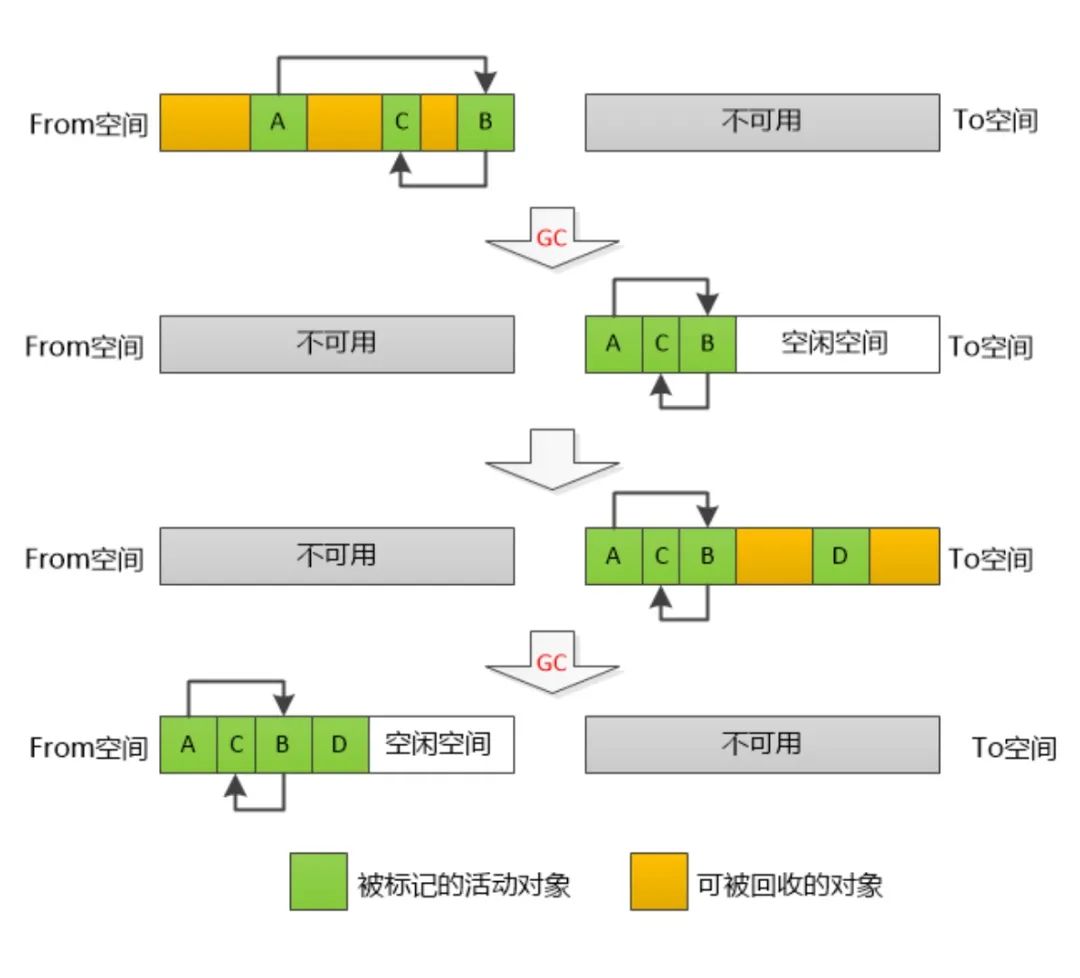
而当一个对象在两次变换中还存在时,就会从新生代区”晋升“到”老生代区“。这一过程被称为对象晋升策略
老生代内存回收
主垃圾回收器负责老生代区的垃圾回收。其中的对象包括新生代区”晋升“的对象和一些大的对象。因此老生代区中的对象有两个特点,对象占用空间大,对象存活时间长
它不会像新生代区那样使用 Scavenge 算法,因为复制大对象所花费的时间长,执行效率并不高。所以它采用标记 - 清除(Mark - Sweep)进行垃圾回收
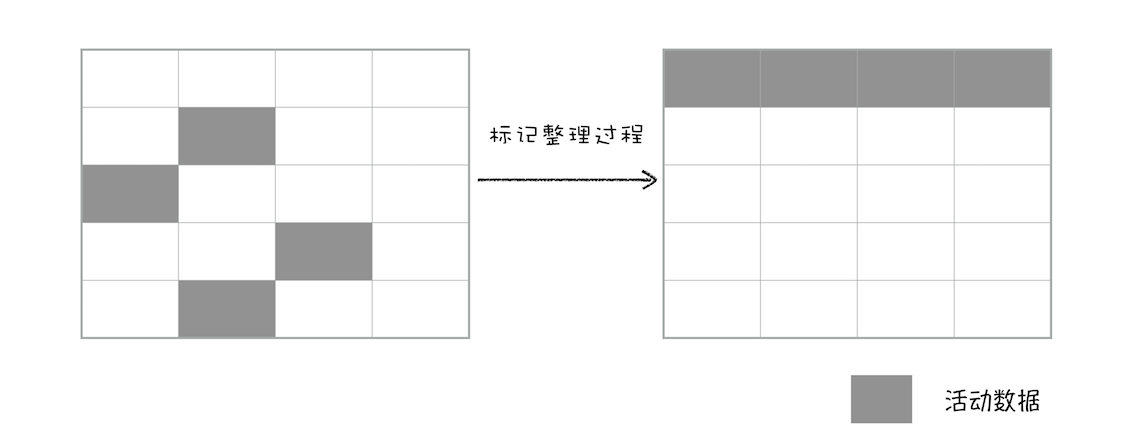
简单来说,先标记,然后清除,但是内存空间里的对象还是不连续,所以引入整理。这就是老生代区的垃圾回收过程 标记 - 清除 - 整理。先标记哪些是要回收的变量,再进行回收(清除),然后将内存空间整理(到一边),这样空间就大了
因为老生代区的对象相对大,虽然采用”标记-清除“算法会比 Scavenge 更快,但架不住卡顿问题。为什么会卡顿?因为 JavaScript 是单线程。为此,V8 将标记过程分为一个个子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,这一算法被称为增量标记算法

而这一行为,与 React Fiber 的设计思路类似,将大任务分割成小任务,因为小,所以执行快,让人察觉不到卡顿
新生代 VS 老生代
- 新生代垃圾回收是临时分配的内存,存活时间短;老生代垃圾回收是常驻内存,存活时间长
- 新生代垃圾回收由副垃圾回收器负责;老生代垃圾回收由主垃圾回收器负责
- 新生代采用 Scavenge 算法;老生代采用「标记-清除」算法
- Scavenge 算法:将空间分为两半,一半是 from 空间,一半是 to 空间。新加入的对象会放在 from 空间,当空间快满时,执行垃圾清理;在角色调换后,当调换完后的 from 空间快满时,再执行垃圾清理,如此反复
- 标记-清理-整理:此为两个算法,「标记-清理」算法和 「标记-整理」算法
- 标记-清理:标记用不到的变量,清理掉
- 标记-整理:清理完内存后,会产生不连续的内存空间,为节省空间,整理算法会将内存排序到一处空间,空间就变大了
引用计数(reference counting)
在 《JavaScript 高级程序设计》中介绍了另一种垃圾回收的机制——引用计数
简单来说:引擎会有张“引用表”,保存了内存里面的资源的引用次数,如果一个值的引用次数是0,就表示这个值不再用到了,因此可以将这块内存释放
但后来这个机制被放弃了,因为它会遇到一个严重的问题:循环引用,从而导致内存泄漏,所以被放弃了
编年体垃圾回收历史
1960年,John McCarthy发表了一篇论文,提出了标记-清除算法。可是标记-清除算法由两个要命的缺点:分配速度慢,容易产生碎片
为了解决这个问题,1963年,Marvin L. Minsky提出了复制算法。而 JavaScript 中的 Scavenge 算法就是以它为基础的改良版本。它的缺点是空间利用率不大,每次只能使用一次
1960年,George E. Collins提出了一个新的 GC 算法:引用计数,缺点是不能回收“循环引用”,目前 JavaScript 的引擎是没有采用这种回收机制
如此,垃圾回收大厦地基已经建好,后人只是在此基础上修修补补
总结
我们介绍了什么是垃圾回收机制,为什么会有垃圾回收机制,以及介绍了垃圾回收的运行机制,它的两种内存采用的不同的垃圾回收算法等等。了解垃圾回收机制,是为了让我们更清晰地明白其运行原理,虽然我们没必要去了解「标记-清理」、「标记-整理」、「Scavenge 」等等算法,但如果明白它们为什么要采用这样的算法有一定的必要性
不然,小白问起网站为什么会卡时,你就可以“无意”透露是不是内存泄漏了啊,然后引出 JavaScript 的垃圾回收机制等,装一次老前辈的经验之谈