


React Router 的实现原理
本文分两部分,一说前端路由的基本原理,二说 React Router 的实现原理
前端路由的基本原理
不说屁话,从时间线上讲,Web 应用原本是后端渲染,后来随着技术的发展,有了单页面应用,慢慢从后端渲染发展成前端渲染
在博客前端路由hash、history的实现 一问中我已经介绍过这两种模式
hash 模式
- 通过监听 hashchange 事件,匹配 hash 值并渲染页面模块
history 模式
- 利用
history.pushState+popState实现 history.pushState能实现不刷新页面,但往历史栈中新增一个记录popState则会在历史记录条目被更改时,触发pushState只会改变历史栈,修改它没有什么API可以监听,所以要与popState配合
简单来说,前端路由的基本原理无非要实现两个功能:
- 监听记录路由变化
- 匹配路由变化并渲染内容
hash模式
hash 模式的实现比较简单,我们通过 hashChange 事件就能直接监听到路由 hash 的变化,并根据匹配到的 hash 的不同来渲染不同的内容。
html
<body>
<a href="#/home">Home</a>
<a href="#/user">User</a>
<a href="#/about">About</a>
<div id="view"></div>
</body>
<script>
function onHashChange() {
const view = document.getElementById("view");
switch (location.hash) {
case "#/home":
view.innerHTML = "Home";
break;
case "#/user":
view.innerHTML = "User";
break;
case "#/about":
view.innerHTML = "About";
break;
default:
view.innerHTML = "Home";
break;
}
}
window.addEventListener("hashchange", onHashChange);
</script>history模式
- 拦截 a 标签的点击事件,阻止它的默认跳转行为
- 使用 H5 的 history API 更新 URL
- 监听和匹配路由改变以更新页面
利用 pushState 往历史栈中添加记录且不刷新页面的特性 + 监听 popstate 浏览器操作导致的 URL 变化
window.history.pushState(state, title, path)window.addEventListener("popstate", onPopState)
html
<body>
<a href="/home">Home</a>
<a href="/user">User</a>
<a href="/about">About</a>
<div id="view"></div>
</body>
<script>
const elements = document.querySelectorAll("a[href]");
elements.forEach(el =>
el.addEventListener("click", e => {
e.preventDefault();
const test = el.getAttribute("href");
history.pushState(null, null, el.getAttribute("href"));
onPopState();
})
);
function onPopState() {
const view = document.getElementById("view");
switch (location.pathname) {
case "/home":
view.innerHTML = "Home";
break;
case "/user":
view.innerHTML = "User";
break;
case "/about":
view.innerHTML = "About";
break;
default:
view.innerHTML = "Home";
break;
}
}
window.addEventListener("popstate", onPopState);
</script>hash模式 VS History模式
| 模式 | 优点 | 缺点 |
|---|---|---|
| Hash | 浏览器兼容性更好,不需要后端路由支持 | 有 # 号 |
| History | 需要现代浏览器,需要后端路由支持 | 无 # 号 |
history 模式下当页面刷新时,因为找不到相对应的路由(因为只有一个页面,路由由前端控制),所以会报404错误,需要在 Nginx(或者服务器)中配置,如果找不到ur,则返回 首页
nginxlocation / { try_files $uri $uri/ /index.html; }
React Router 的实现原理
先用最简单的话来概括一下 React Router 到底做了什么?
本质上, React Router 就是在页面 URL 发生变化的时候,通过我们写的 path 去匹配,然后渲染对应的组件。
那么,我们想一下如何分步骤实现:
- 如何监听 url 的变化 ?
- 如何匹配 path ?
- 渲染对应的组件
换句话说,也是一个组件,通过渲染不同的组件来控制路由切换
整体设计
我们用一张图来理解一下整个 react-router 是怎么实现的:
接下来我们看看每一个步骤是怎么实现的。
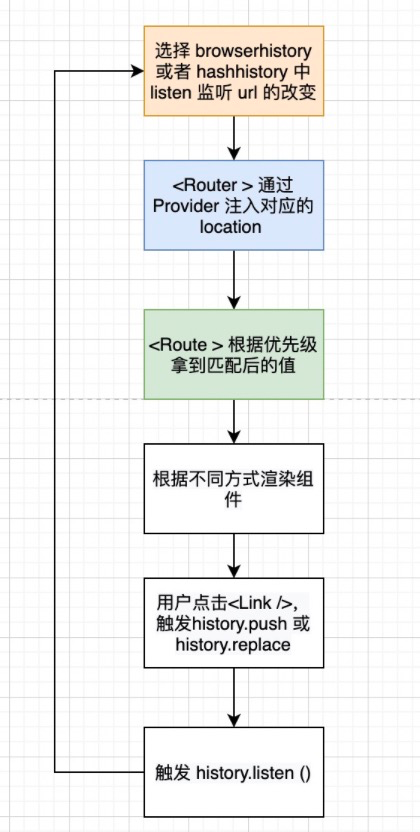
如何监听 url 的变化 ?
正常情况下,当 URL 发生变化时,浏览器会像服务端发送请求,但使用以下 3 种办法不会向服务端发送请求:
- 基于 ajax(实现起来很麻烦)
- 基于 hash
- 基于 history
react-router 使用了 history 这个核心库。它本质是屏蔽不同模式下载监听实现上的差异,使用发布订阅模式 来实现,这里不做探究
总结
从后端路由到前端路由,最大的改变是体验,体验更良好了
前端路由模式有两种:hash 模式 和 history 模式,两者分别利用浏览器自由特性实现单页面导航
- hash 模式:window.location 或 a 标签改变锚点值,window.hashchange() 监听锚点变化
- history 模式:history.pushState()、history.replaceState() 定义目标路由,window.popstate() 监听浏览器操作导致的 URL 变化
React Router 匹配路由由 mathPath 通过 path-to-regexp 进行,<Route> 相当于一个高阶组件,以不同的优先级和匹配模式渲染匹配到的子组件
React Router 的主要组件源码,整体的实现:
- 对于监听功能的实现,React Router 引入了
history库,以屏蔽了不同模式路由在监听实现上的差异, 并将路由信息以context的形式,传递给被<Router>包裹的组件, 使所有被包裹在其中的路由组件都能感知到路由的变化, 并接收到路由信息 - 在匹配的部分, React Router 引入了
path-to-regexp来拼接路径正则以实现不同模式的匹配,路由组件·<Route>作为一个高阶组件包裹业务组件, 通过比较当前路由信息和传入的 path,以不同的优先级来渲染对应组件