


模拟题一
1. CSS:BFC 是什么
一句话解释:BFC 是块级格式化上下文,它的作用有清除内部浮动、margin 塌陷、垂直 margin 合并、自适应布局,可通过overflow: hidden 等方法触发
文档流
文档流分 定位流、浮动流、普通流
BFC 属于普通流,其他的有
- IFC:行级格式化上下文, inline 内联
- GFC:网格布局格式化上下文,display: grid
- FFC:自适应格式化上下文, display: flex,或 display: inline-flex
BFC 是什么
块级格式化上下文,是块级盒子的布局过程发生的区域,也是浮动元素与其他元素交互的区域
具有 BFC 特性的元素可以看作是隔离了的独立容器,容器里面的元素不会在布局上影响到外面的元素,并且 BFC 具有普通容器所没有的一些特性
通俗讲:BFC 是一个封闭的大箱子,箱子内部无论如何折腾,就不会影响到外部
如何触发 BFC
- 根元素(html)
- 浮动元素(float 的值不为 none 的元素)
- 绝对定位元素(position 的值为 absolute 或 fixed 的元素)
- 行内块元素(display 的值为 inline-block 的元素)
- 表格单元格(display 的值为 table-cell,HTML 表格单元格默认值)
- 表格标题(display 的值为 table-caption,HTML 表格标题默认值)
- overflow 的值不为 visible 或 clip 块级元素
- 弹性元素(display 的值为 flex 或 inline-flex 元素的直接子元素)
- 网格元素(display 的值为 grid 或 inline-grid 元素的直接子元素)
详见:MDN
BFC的特征
- BFC 是页面上的一个独立容器,容器里面的元素不会影响外面的元素
- BFC 内部的块级盒会在垂直方向上一个接一个排列
- 同一 BFC 下的相领块级元素可能发生外边距重叠,创建新的 BFC 可以避免外边距重叠
- 每个元素的外边距盒(margin box)的左边与包含块边框盒(border box)的左边相接触(从右向左的格式的话,则相反),即使存在浮动
- 浮动盒的区域不会和 BFC 重叠
- 计算 BFC 的高度时,浮动元素也会参与计算
BFC 有什么用
- 修复浮动元素造成的高度塌陷问题
- 子元素浮动,引起高度为0,父元素加上 BFC(overflow: hidden),撑起高度
- margin 塌陷
- 垂直 margin 合并
- 实现灵活健壮的自适应布局
相关文章:CSS 世界中的结界——BFC
2. 手写源码:防抖与节流
防抖
无论触发多少次,一定在事件触发后的 n 秒后执行,如果你在一个事件触发 n 秒内又触发了这个事件,以新的事件的时间为准,n 秒后再执行。总之,触发事件 n 秒内不再触发事件,n 秒后再执行
应用场景
- 调整浏览器窗口大小
- 搜索框输入(输入后 1000 毫秒搜索)
- 表单验证(输入 1000 毫秒后验证)
javascript
function debounce(func, wait, flag) {
let timer = null;
return function (...args) {
clearTimeout(timer);
if (!timer && flag) {
func.apply(this, args);
}
timer = setTimeout(() => {
func.apply(this, args);
}, wait);
};
}
// flag 是否立即执行节流
不管事件触发频率多高,只在单位时间内执行一次
应用场景
- 滚动监控(计算位置信息)
- 周期性事件(比如每隔一段时间更新页面数据)
- 无限滚动加载
实现方法
时间戳/定时器
时间戳:第一次肯定触发,最后一次不执行
定时器:第一次不执行,最后一次肯定触发
时间戳
javascript
function throttle(func, wait) {
let pre = 0;
return function (...args) {
if (Date.now() - pre > wait) {
pre = Date.now();
func.apply(this, args);
}
};
}定时器
javascript
function throttle(func, wait) {
let timer = null;
return function (...args) {
if (!timer) {
timer = setTimeout(() => {
timer = null;
func.apply(this, args);
}, wait);
}
};
}结合版本,第一次和最后一次都会触发
javascript
function throttle(func, wait) {
let pre = 0,
timer = null;
return function (...args) {
if (Date.now() - pre > wait) {
clearTimeot(timer);
timer = null;
pre = Date.now();
func.apply(this, args);
} else if (!timer) {
timer = setTimeout(() => {
func.apply(this, args);
}, wait);
}
};
}衍生问题:手写apply、箭头函数和普通函数有什么区别、数组和类数组的区别
手写 apply
javascript
function myApply(context = window, args) {
if (this === Function.prototype) {
return undefined;
}
let fn = Symbol();
context[fn] = this;
let result;
if (Array.isArray(args)) {
result = context[fn](...args);
} else {
result = context[fn]();
}
delete context[fn];
return result;
}箭头函数和普通函数有什么区别
- 箭头函数没有 this 对象,函数体内的 this 是定义时所在的对象,而不是使用时的对象
- 不可以当作构造函数使用,也就是说,不可以对箭头函数使用 new 命令,否则会抛出一个错误
- 不可以使用 arguments 对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替
- 不可以使用 yield 命令,因此箭头函数不能用作 Generator 函数
- 衍生 generator 函数。生成器,yield,开始,中断
数组和类数组的区别(arguments)
- 数组是数组,类数组是对象
- 类数组是拥有 length 属性和索引属性的对象
- 区别:类数组是对象,它的原型关系和数组不同
常见的类数组还有
- 用 getElementsByTagName/ClassName() 获取的 HTMLCollection
- 用 querySelector 获取的 nodeList
类数组如何转换为数组
以下几种方法都可以将类数组转换为数组:
Array.from(likeArray)展开运算符:
[...likeArray]Array.prototype.slice(likeArray, 0)Array.prototype.concat.apply([], arguments)
相关文章:防抖与节流
3.闭包
什么是闭包?
闭包就是一个绑定了执行环境的函数,它利用词法作用域的特性,在函数嵌套时,内层函数引用外层函数作用域下的变量,并且内层函数在全局环境下可访问,就形成了闭包
闭包的优缺点
- 优点
- 保护私有变量
- 避免全局变量污染
- 让一些变量始终存在内容中(是优点)
- 缺点
- 一直存在内存中(也是缺点)
闭包的应用
应用场景有两处,一是作为返回值,二是作为参数传递
像函数式编程、面向事件编程、模块化、私有实例变量都是闭包的应用场景
衍生问题: add(1)(2)(3)
实现 add(1)(2)(3)
javascript
function add(x, y, z) {
return x + y + z;
}
const curried = (fn, ...args) => {
if (args.length >= fn.length) {
return fn(...args);
}
return (...args2) => curried(fn, ...args, ...arg2);
};
const curriedAdd = curried(add);
curriedAdd(1)(2)(3);
curriedAdd(1)(2, 3);
curriedAdd(1, 2)(3);相关文章:闭包
4.Promise 是什么
Promise 是 JavaScript 中用于处理异步操作的一种解决方案。它可以让异步代码的执行看起来更像同步代码,从而提高代码的可读性和可维护性,与之比较的是传统的回调函数
Promise 有三种状态:pending(等待)、fulfilled(成功)和 rejected(失败),Promise 的状态只能从 pending 转变为 fulfilled 或 rejected,且一旦状态确定就不会再改变
Promise 的实现原理如下:
- 每个 Promise 实例都有一个 then 方法,用于注册成功和失败的回调函数
- 当异步操作完成时,Promise 实例会自动调用相应的回调函数,并将结果传递给回调函数
- Promise 使用微任务队列来管理回调函数的执行顺序,保证了代码的执行顺序
- Promise 还支持链式调用,可以在 then 方法中返回一个新的 Promise 实例,从而实现复杂的异步流程控制
衍生问题:手写 Promise.all 、手写 Promise.allSettle
手写 Promise.all
javascript
function all(iterable) {
return new Promise((resolve, reject) => {
const results = new Array(promises.length);
let completedCount = 0;
promises.forEach((promise, index) => {
// 确保即使是非 Promise 的值也能处理
Promise.resolve(promise)
.then(value => {
results[index] = value;
completedCount++;
// 当所有 Promise 都成功时
if (completedCount === promises.length) {
resolve(results);
}
})
.catch(reason => {
// 如果任何一个 Promise 失败,则立即 reject
reject(reason);
});
});
// 如果传入的是空数组,则直接 resolve 空数组
if (promises.length === 0) {
resolve(results);
}
});
}Promose.all 的缺陷在于只要其中任何一个 promise 失败都会执行 reject,并且 reject 是第一个抛出的错误信息,只有所有的 promise 都 resolve 时才会调用 .then 中的回调函数
手写 Promise.allSettled
javascript
function allSettled(promises) {
return new Promise((resolve) => {
const results = new Array(promise.length);
let completedCount = 0;
promises.forEach((promise, index) => {
Promise.resolve(promise)
.then((value) => {
results[index] = {
status: 'fulfilled',
value,
}
})
.catch(reason => {
results[index] = {
status: 'rejected',
reason,
}
})
.finally(() => {
completedCount++
if (completedCount === promises.length) {
resolve(results)
}
})
})
})
}Promise.all 和 Promise.allSettled 最大的不同:Promise.allSettled 永远不会被 reject
5. Fiber 是什么,为什么需要 Fiber
什么是 React Fiber
- Fiber 是 React 内部的一种新的协调算法,用于对 React 组件树进行调度和渲染
- 它使用了一种基于链表数据结构来表示组件树(称之为Fiber树),这个数据结构允许 React 执行更加颗粒的控制和分段计算
为什么需要 React Fiber
- 在 React 16 之前面临的主要性能问题是:当组件很庞大时,更新状态可能造成页面卡顿,根本原因在于更新流程是同步、不可中断的。React 16 重写了代码,提出 Fiber 架构,它是可异步中断的
- 传统的 React Reconciler 算法存在一些问题,例如无法暂停、恢复或者放弃正在执行的工作,这会导致高优先级的任务被阻塞
- React Fiber 通过将组件树的递归更新拆分为多个子任务,使 React 可以对任务进行暂停、恢复和放弃等操作,从而提高用户交互的响应性
- Fiber 还支持增量渲染,可以将渲染工作分批完成,而不是一次性完成,从而使得 React 应用在执行大量计算时也能保持流畅的用户体验
Fiber 的工作原理
- Fiber 中使用了一种基于链表的数据结构来表示组件树,称为 Fiber 树
- Fiber 树中的每个节点就是一个 Fiber 对象,包含了组件的状态信息和更新操作
- React 在更新组件时,会根据新旧 Fiber 树之间的差异计算出需要更新的部分,并将更新任务拆分成多个子任务
真实 DOM 对应在内存中的 Fiber 节点会形成 Fiber 树,这棵 Fiber 树在 React 中叫 current Fiber,也就是当前 DOM 树对应的 Fiber 树,而正在构建 Fiber 树的叫 workInProgress Fiber,这两棵树的节点通过 alternate 相连
Fiber 的渲染流程
- 初次渲染:当应用首次启动时,会构造一颗全新的 Fiber 树,即创建虚拟 DOM 并将其转换为 Fiber 节点
- 数据更新:当应用的状态发生变化时,React 会比较新旧两棵 Fiber 树,找到差异并更新到真实 DOM
- 渲染过程:
- 输入阶段:从 react-dom 包开始,将更新请求传递给调度器(Scheduler)
- 调度阶段:调度起将更多任务拆分成多个工作单元,并根据优先级分批执行
- 提交阶段:完成所有工作单元后,将变更应用到真实 DOM
- 中断与恢复:Fiber 架构支持将渲染过程中断并恢复,以确保应用的响应性
相关文章:Fiber 的作用和原理
6. 数据流: Redux 是什么?
Redux 是 JavaScript 状态容器,能提供可预测化的状态管理
它认为:
- Web 应用是一个状态机,视图与状态时一一对应的
- 所有的状态,保存在一个对象里
单一数据源、state 只读、使用 reducer 纯函数修改数据
Redux 是一个用户管理应用状态的开源 JavaScript 库,它提供了一种可预测的状态容器,帮助应用开发更加一致和可维护。Redux 基于 Flux 架构模式,采用单一数据源的方式管理应用的全局状态
Redux 的核心概念包括:
- Store:存储应用的整个状态
- Action:描述应用状态变化的事件
- Reducer:根据 Action 更新 Store 中的状态
Redux 的工作流程如下:
- 用户在应用中触发某个事件,比如点击按钮
- 应用分发一个 Action 对象,描述这个事件
- Reducer 函数接收这个 Action,并根据其更新 Store 中的状态
- Store 中的状态发生变化,React 组件会感知到这个变化并重新渲染
Redux 是状态管理库,不仅适用于 react,还可以作用于 vue
它的特点是一个 store、reducer 纯函数、通过 dispatch 一个 action 来修改 store
即用户 dispatch 一个动作,传给纯函数 reducer,reducer 接受两个参数,一个为原本的 store,另一个为动作,调用完毕后返回新的 store,用户监听 store 变化,就能实时知道 store 的变化
Redux 的主要优点包括:
- 提供可预测的状态管理方式,增强应用的可维护性
- 单一数据源使得状态更新更加清晰和可控
- 通过纯函数 Reducer 实现状态更新,增强代码的可测试性
- 与 React 配合良好,有利于构建复杂的、大规模的 Web 应用
衍生问题:React-Redux是什么?Mobx 是什么?dva是什么?zustand 是什么?
React-Redux是什么
React-Redux 是专门为 React 应用程序设计的状态管理库。它是 Redux 库的一个绑定层,提供了将 Redux 状态管理和 React 组合结合的方式
典型的工作流程:
- 创建 Redux store 并定义 action、reducer 等
- 使用 connect 函数将 React 组件与 Redux store 进行绑定
- 在组件中通过 mapStateToProps 和 mapDispatchToProps 访问和更新状态
- 当状态发生变化时,React-Redux 会自动触发组件的重新渲染
Mobx 是什么
Mobx 是一个轻量级的状态管理库,它通过观察者模式来管理应用程序的状态。与 Redux 等单向数据流框架不同,Mobx 采用的是响应式编程的思想
工作流程如下:
- 定义可观察的状态(observable)
- 创建衍生状态(computed)
- 订阅状态变化并更新 UI(observer)
- 通过 action 修改状态
dva是什么
Dva 是一个基于 Redux 和 React-Router 的轻量级前端框架,它提供了一种更加简单和声明式的方式来管理 React 应用程序的状态
定义 model、注册 model 到 dva 应用,使用 connect 连接组件和 model
zustand 是什么
Zustand 是一个简单、轻量级的 JavaScript 状态管理库,主要用于 React 应用程序。它提供了一种全新的、基于 Hooks 的状态管理方式,旨在解决 Redux 等库的复杂性和样板代码问题
使用 Zustand 的典型流程如下:
- 创建一个 store,定义状态和更新状态的 actions
- 在组件中使用 useStore hook 订阅和更新状态
- 如果需要,可以创建多个子 store 进行模块化管理
7. 浏览器输入 url 到页面渲染都经历了什么
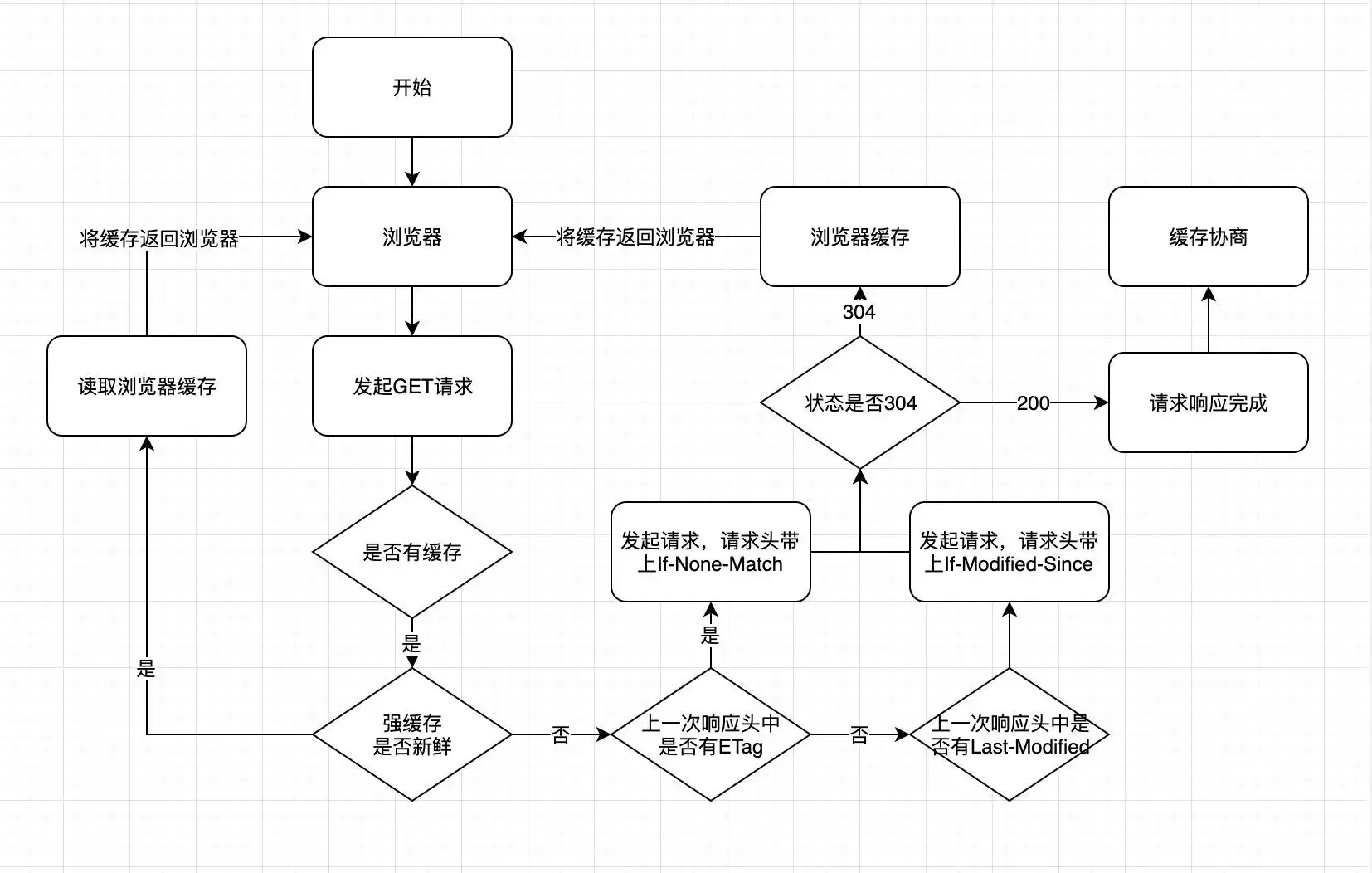
输入 url,敲击键盘,浏览器判断输入的 url 是否为网址,如果不是网址,再通过浏览器默认搜索引擎拼接输入的值,前往搜索引擎页面;如果是网址,则构建请求。
浏览器判断是否有缓存,如果有,则返回资源给浏览器(之后浏览器进行解析),如果没有,则先判断DNS是否有缓存,如果有直接返回 ip 地址,如果没有则 DNS 解析,并缓存 DNS。
获取后等待 TCP 连接,建立连接后,发起 HTTP 请求,服务器返回状态和数据。判断是否与打开的网址是同一个站点,如果是,使用相同的渲染进程渲染页面,如果不是,浏览器渲染 HTML、CSS、JS。经历重绘与回流最终构建出渲染树,GUI 线程接管渲染页面
其中缓存部分,先判断它是否有强缓存再判断协商缓存。执行顺序为:先判断 Cache-Control (HTTP 1.1)是否失效,未失效返回缓存;失效则判断 Expires(HTTP 1.0) 是否失效,未失效返回缓存;失效则判断协商缓存 ETag(HTTP 1.1),请求时请求头中带有条件请求If-No-Match,判断状态是否为304,如果是则资源未变,返回缓存内容,如果不是,则请求服务器返回资源并缓存住缓存信息(Cache-Control 以及 ETag 等);如果 ETag 不可用,则判断上次响应中是否有Last-Modified,如果是,则发起请求,请求投中带有条件请求 If-Modified-Since,逻辑与 If-No-Match 一样
整体流程图:
衍生问题:重绘与回流
重绘与回流
重绘是元素的样式发生改变,不影响它所在的文档流的位置
回流是元素的尺寸、结构或者某些属性发生改变,浏览器需要重新计算它所在的位置,然后重新渲染页面的过程
回流必定会触发重绘,但重绘不一定会引起回流
相关文章:从 url 输入到返回请求的过程
相关文章:面试常客:HTTP 缓存
8. HTTP 1、2、3 的区别
HTTP 的发展史
HTTP1
HTTP1.1
HTTP2
HTTP3
HTTP1 没有 keep-alive ,每次发送请求,都要连接一个 tcp
HTTP1.1 加了 connect: keep-alive,复用一个 TCP 连接
缺点是工作流程是请求-响应,请求发出去后等待响应,然后再发送请求,但对同一个服务器来说,可以建立6 个 tcp 连接。所以理论上最多可以同时请求 6 个文件
这个现象叫做:队头阻塞
解决方案
并发连接(多建立几个 TCP 连接,一个服务器最多建立 6 个 TCP 连接)
域名分片:一个域名最多并发六个长连接,那我多个域名
多路复用:HTTP2 的解决方案
HTTP2 多路复用
多路复用特点:把请求和响应当作一个流,每个流都有一个 id,每个流可以有多个帧,帧上保留数据
即相同域名多个请求,共享同一个 TCP 连接,降低了延迟
工作原理如下:
- 客户端和服务器建立一个 TCP 连接后,就可以同时发送多个 HTTP 请求
- 每个请求和响应都会分配一个唯一的流(Stream)标识符
- 流之间是并行独立的,互不干扰
- 服务器可以交错地发送请求的响应数据包,客户端能够根据流 ID 将其重新组装
HTTP2的其他特点:请求优先级,二进制传输,数据流,服务器推送,头部压缩
缺点是:TCP 会丢包
HTTP3
解决 TCP 连接的问题
HTTPS
在 HTTP 的基础上加了一层 SSL 协议,为加密协议
HTTP 缓存
HTTP 缓存分为强缓存和协商缓存
强缓存
HTTP 1 是 expires,设置过期时间来判断
HTTP 1.1 是 cache-control 设置过期时长来判断
cache-control:max-age=1000
同时存在时,cache-control 的优先级大于 expires
协商缓存
HTTP 1.0 通过 last-modified,即最后修改时间来判断是否过期
HTTP 1.1 通过 etag,生成文件唯一标识来判断是否过期
从精准度的角度看,etag 比 last-modified 强(last-modified 的感知单位是秒)
从性能角度看,last-modified 比 etag 强
两则同时存在时,etag 的优先级大于 last-modified
HTTP 状态码
301 - 永久重定向
302 - 临时重定向
304 - 协商缓存重定向
401 - 未授权
403 - 服务器收到请求,但是拒绝提供服务,即资源不可用
404 - 无法找到请求资源
408 - 请求超时
414 - 请求 URI 过长
更多内容:HTTP 状态码
9. 你常用的性能优化
HTTP方面优化
开启 HTTP2(特点:对头阻塞)
使用缓存:利用 HTTP 缓存、代理服务器缓存(开启 gzip 压缩)、应用程序缓存等减少重复请求
减少 HTTP 请求(开启 HTTP2 后这就不是个问题了):合并 CSS、JavaScript 和图片文件,减少页面加载时的 HTTP 请求输了
使用 CDN:OSS/CDN 可以将静态资源分发到全球各个服务器
- 一些比较大的图表库(如echart/map),可以放在 CDN 上,减少总包的体积,加快访问速度
服务器开启 gzip 压缩
页面渲染优化
- 减少 DOM 操作:尽量减少对 DOM 的操作,例如使用事件委托、CSS 动画
- 使用懒加载:懒加载可以延迟加载非关键资源,从而提高页面加载速度
- 使用服务器渲染(SSR):服务端渲染可以在服务器端生成 HTML 页面,减少客户端的加载时间
- 首屏静态html:既然要加快,那就做到极致,首屏是个静态页
- 使用 Web 字体:使用 Web 字体代替图片可以减少“资源”文件数量及加载时间
- 如果使用中文字体,可使用字蛛减少字体大小
- 优化图片格式、大小:压缩图片大小、使用 WebP 、AVIF格式、懒加载图片等方式可以减少加载时间
- 将 CSS 放头部、JavaScript 脚本放尾部
- 防抖节流
- 减少回流(重排)和重绘
- CSS 书写顺序
- async defer
Webpack 等打包工具的性能优化
- 拆包
- 配置 Webpack,压缩 JS、CSS、图片等静态资源大小(资源压缩)
- Tree shaking 去除死代码(生产模式自动做 Tree shaking)
- 使用最新版本的 webpack 或者是其他性能更好的打包库
React 框架做的事情
- 使用 usememo(缓存值)、useCallback(缓存回调函数)+ memo(避免重复渲染)
- 路由懒加载(使用 react.lazy)
- 组件懒渲染
- Suspense
- 分页
- 虚拟列表
- 列表项使用 key 属性
- 第三方插件按需引入
- 使用 Fragment 或者空标签减少层级
- SSR 渲染
图片的优化
图片动态裁剪
图片懒加载
- 图片懒加载实现原理
- 先通过 HTML 自定义属性 data-xxx 先暂存 src 的值,然后在图片出现在屏幕可视区域时,再将 data-xxx 的值赋值到 img 的scr 属性即可
使用字体图标
图片转 base64 格式
图片资源压缩
- tinypng 图片资源压缩
图片资源放到 OSS 上
图片格式转换
- 转成 webp、AVIF格式更现代的压缩图片格式
路由懒加载
单页面应用,一个路由对应一个页面
jsx
import React, { Suspense } from 'react';
const OtherComponent = React.lazy(() => import('./OtherComponent'));
function MyComponent() {
return (
<div>
<Suspense fallback={<div>Loading...</div>}>
<OtherComponent />
</Suspense>
</div>
);
}路由懒加载的原理
懒加载前提的实现:ES6 的动态加载模块——import(),它返回的是一个 promise
当 webpack 解析到 import 语法时,会自动进行代码分割
合理的 Tree Shaking
作用:消除无用的 JS 代码,减少代码体积
Tree-Shaking 原理
依赖 ES6 的模块特性,ES6 模块依赖关系是确定的,和运行时的状态无关,可以进行可靠的静态分析
简单来说,根据 ES Modules 的静态分析
组件懒渲染
当组件进入或即将进入可视区域时才渲染组件。常见的组件 Modal/Drawer 等,当 visible 属性为 true 时才渲染组件内容,也可以认为是懒渲染的一种实现
React.memo 减少React子组件渲染
配合 React.useCallback 和 React.useMemo
使用骨架屏或加载提示
在项目打包时将骨架屏的内容直接放在 HTML 文件的根节点上
长列表虚拟滚动
只渲染可视区域的列表项,非可见区域的不渲染
虚拟列表的原理
计算出列表总高度,并在触发滚动事件时根据 scrollTop 值不断更新 startIndex 以及 endIndex,以此从列表数据 listData 中截取对应元素
虚拟滚动的缺点:
频繁的计算导致会有短暂的白屏现象,可以通过节流来限制触发频率
加上为列表管理加一些“上、下缓冲区”,即在可视区域之外预渲染一些元素
通过 IntersectionObserver 和 getBoundingClientRect 也可实现
Web Worker 优化长任务
由于浏览器 GUI 渲染线程与 JS 引擎线程是互斥关系,所以当页面中有长任务时,会造成页面 UI 阻塞,出现界面卡顿、掉帧等情况
一些需要大量计算的数据可以放在 web worker 上计算,计算好后再塞入页面中
JS 的六种加载方式
正常模式
html
<script src="index.js"></script>这种情况下 JS 会阻塞 DOM 渲染
async 模式
html
<script async src="index.js"></script>异步模式,JS 不会阻塞 DOM 的渲染,async 加载是无顺序的,当它加载结束,JS 会立即执行
使用场景:埋点统计、客服系统
defer 模式
html
<script defer src="index.js"></script>defer 模式下,JS 的加载也是异步的,但 defer 资源会在 DOMContentLoaded 执行之前,并且 defer 是有顺序的加载
module 模式
html
<script type="module">import { a } from './a.js'</script>在主流现代浏览器中,script 标签的属性可以加上 type="module",浏览器会对内部的 import 引用发起 HTTP 请求,获取模块内容。这时 script 的行为会像是 defer 一样,在后台下载,并且等待 DOM 解析
Vite 就是利用浏览器支持原生的 es module 模块,开发时跳过打包的过程,提升编译效率
preload
html
<link rel="preload" as="script" href="index.js">link 标签的 preload 属性:用于提前加载一些需要的依赖,这些资源会优先加载
preload 特点
preload 加载的资源是在浏览器渲染机制之前进行处理的,并不会阻塞 onload 事件
preload 加载的 JS 脚本其加载和执行的过程是分离的,即 preload 会预加载相应的脚本代码,待到需要时自行调用
prefetch
html
<link rel="prefetch" as="script" href="index.js">prefetch 是利用浏览器的空闲时间,加载页面将来可能用到的资源的一种机制;通常可以用于加载其他页面(非首页)所需要的资源,以便加快后续页面的打开速度
prefetch 特点:
prefetch 加载的资源可以获取非当前页面所需资源,并且将其放入缓存至少五分钟
当页面跳转时,未完成的 prefetch 请求不会被中断
加载方式总结
async、defer 是 script 标签的专属属性,对于网页的其他资源,可以通过 link 的 preload、prefetch 属性来预加载
现代框架已经将 preload、prefetch 添加到打包流程中,通过配置可以使用
衍生问题:性能指标、白屏监控
性能指标
pagespeed 或者 Chrome DevTools (Lighthouse)可以分析一个网站的性能、无障碍、最佳做法以及SEO
三大核心指标(Core Web Vitals)(2020年 Chrome提出)
Largest Contentful Paint(LCP):最大内容绘制。
加载性能指标。2.5s 内加载完视为优秀Interaction to Next Paint(INP):从交互到下一次绘制的延时。
交互体验指标。200ms 内视为优秀Cumulative Layout Shift(CLS):累计布局偏移。
视觉稳定性指标,100ms 内视为优秀First Input Delay(FID):首次输入延时。
交互体验指标,100ms 内执行完视为优秀PS:2024 年 3 月 INP 取代 FID
因为 FID 有一些局限性
- 首次:FID 只上报用户第一次与页面交互的响应性。虽然第一次交互很重要,但并不代表整个页面声明周期
- 输入延迟:FID 只测量首次交互的输入延时,即交互开始到事件开始处理这段时间,而事件处理和渲染的耗时,没有被统计
所以有了新的指标INP,它不仅测量首次交互,而且还测量所有的交互延时。除了输入延时,还包括事件处理时长、渲染延时。它的目标是确保从用户开始交互到下一帧绘制的时间尽可能短,以满足用户进行的所有或大多数交互
以用户为中心的性能指标
- First Paint(FP):首次绘制时间
- 页面第一次绘制像素的时间,2s内优秀
- First contentful paint(FCP):首次内容绘制时间
- 首次渲染出内容(文本、图像等)的时间,理想值应小于1秒
- Largest contentful paint(LCP):最大内容渲染时间
- 视窗内最大元素绘制的时间,2.5s内优秀
- Interaction to Next Paint(INP):从交互到下一次绘制的延时。
- 交互体验指标。200ms 内视为优秀(代替 FID)
- First input delay(FID):首次输入延迟
- 当用户第一次与站点交互(点击按钮)的浏览器响应的时间,100ms内优秀
- 后被 INP 代替
- Time to interactive(TTI):可交互时间
- 用户首次可以与页面进行有意义互动的时间
- JS 未执行完、长任务阻塞
- Total blocking time(TBT):总阻塞时间
- FCP 到 TTI 之间长任务的阻塞时间,总体阻塞用户输入的时间段
- Cumulative layput shift(CLS):累积布局偏移
- 测量页面视觉稳定性
- DOMContentLoaded:浏览器已完全加载 HTML,并构建了 DOM 树,但像
<img>和样式表之类的外部资源可能尚未加载完成 - load:浏览器不仅加载完成了 HTML,还加载完成了所有外部资源:图片,样式等
白屏监控
白屏通常指的是页面打开后,浏览器上面的地址栏已经显示完整的 URL,但是页面内容无法渲染,只有白色的空白页面。
导致白屏的原因大致可分为两类:
- 资源加载问题
- 代码执行错误
从现代前端视角来看,这两种原因都跟当前SPA框架的广泛使用有关。
白屏检测的方法有以下几种
1.检测根节点是否渲染
这种方法的原理是在当前主流 SPA 框架下,DOM 一般挂载在一个根节点之下(比如 <div id="app"></div> ),发生白屏后通常是根节点下所有 DOM 被卸载。
2.Mutation Observer 监听 DOM 变化
可以通过 Mutation Observer 来监听 DOM 树变化,从而判断页面是否白屏。
3.页面截图
通过对网页进行截图,对截图进行像素点分析,判断页面是否白屏。
10.算法题:两数之和
javascript
function twoSum(target, nums) {
let map = new Map();
for (let i = 0; i < nums.length; i++) {
let diff = target - nums[i];
if (map.has(diff)) {
return [map.get(diff), i]
}
map.set(nums[i], i)
}
}